![]() Tutaj umieszczamy wybrane zagadnienia związane z techniką mówienia i śpiewania (źródło: www.wikipedia.pl).
Tutaj umieszczamy wybrane zagadnienia związane z techniką mówienia i śpiewania (źródło: www.wikipedia.pl).
Jeśli intersują Cię jakieś inne zagadnienia, do nas.
Spis treści
- Barwa dźwięku
- Dyszkant
- Fale dźwiękowe
- Falset
- Fonetyka
- Generowanie głosu
- Glissando
- Intonacja
- Kamerton
- Kastrat
- Klasyfikacja głosów
- Legato
- Melizmat
- Metronom
- Ozdobnik
- Powstawanie dźwięku w fałdach głosowych
- Przewodzenie dźwięków drogą powietrzną
- Rejestry głosu
- Słuch
- Staccato
- Śpiew
- Techniki śpiewu
- Tonacja
- Vibrato
- Wokaliza
Dyszkant – jest to chłopięca odmiana głosu ludzkiego. Najczęściej ten rodzaj głosu posiadają chłopcy przed mutacją. Z dyszkantem jest związany klucz dyszkantowy bardzo podobny do wiolinowego. Po mutacji mężczyźni mówią odpowiednim głosem męskim i (jeśli potrafią) odpowiednikiem dyszkantu – falsetem.
![]()
Przez powietrze docierają do małżowiny usznej, następnie przewodem słuchowym zewnętrznym do błony bębenkowej. Pod wpływem drgań powietrza błona bębenkowa porusza przylegający do niej młoteczek. Drgania z młoteczka są przekazywane na kowadełko i strzemiączko, za pośrednictwem okienka owalnego trafiają do ucha wewnętrznego, gdzie drgania są zamieniane na impulsy nerwowe, które nerwem słuchowym docierają do ośrodków słuchowych w korze mózgowej.
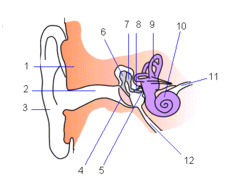 Budowa ucha ludzkiego: 1 – czaszka 2 – przewód słuchowy zewnętrzny 3 – małżowina uszna 4 – błona bębenkowa 5 – okienko owalne 6 – młoteczek 7 – kowadełko 8 – strzemiączko 9 – kanał półkolisty 10 – ślimak 11 – nerw słuchowy 12 – trąbka Eustachiusza
Budowa ucha ludzkiego: 1 – czaszka 2 – przewód słuchowy zewnętrzny 3 – małżowina uszna 4 – błona bębenkowa 5 – okienko owalne 6 – młoteczek 7 – kowadełko 8 – strzemiączko 9 – kanał półkolisty 10 – ślimak 11 – nerw słuchowy 12 – trąbka Eustachiusza
Falset (z wł. falsetto) fistuła – zwyczajowo mianem falsetu określa się rodzaj wysokiego głosu męskiego o groteskowym brzmieniu. Faktycznie oznacza jednak śpiew na niedomkniętych strunach głosowych zarówno u mężczyzn, jak i u kobiet. Realizowany jest poprzez silne, nienaturalne napięcie strun głosowych, przez co drgają w krótszej niż odpowiednia dla danego dźwięku długości, powodując wydobycie dźwięku o niewielkiej dynamice oraz charakterystycznej nosowej barwie. Nazwa pochodzi od włoskiego falso – „fałszywe”.
Jednym z najbardziej znanych wykonawców rockowych śpiewających falsetem jest Tom Keifer, wokalista i gitarzysta amerykańskiego zespołu hardrockowego Cinderella, czy chociażby King Diamond, lider zespołu Mercyful Fate oraz eponimicznej formacji King Diamond. Efektywnie wykorzystują falset tacy wykonawcy, jak związany z awangardą rockową i zespołem Soft Machine Robert Wyatt i jeden z najsłynniejszych muzyków brazylijskich Milton Nascimento.
Falset spotykany jest w muzyce operowej oraz w folklorze muzycznym (na przykład jodłowanie w Szwajcarii i Tyrolu). Często używana nazwa dla męskiego falsetu to kontratenor.
![]()
Inne cechy foniczne (tj. związane z głosem), takie jak akcent, intonacja, iloczas (cechy prozodyczne), leżą w zasadzie na pograniczu fonetyki i fonologii. Można je zaliczyć do fonetyki, albowiem dotyczą „dźwiękowej substancji języka” (jak fonetyka; patrz „Encyklopedia językoznawstwa ogólnego” – dalej: EJO), fonetyka musi się nimi zająć, by odpowiedzieć na pytanie o ich właściwości, realizację itp., i dlatego w podręcznikach znajdują się w dziale fonetyki. Jednak z drugiej strony bada się je głównie w celu określenia funkcji, a to jest już kategoria fonologii, stąd prozodię zalicza się do fonologii. Takie rozstrzygnięcie (zaliczenie prozodii do fonologii) zawiera EJO. peiofw
Fonetykę można również zróżnicować ze względu na ilość języków, które bada – fonetyka opisowa bada jeden język, a fonetyka porównawcza dotyczy dwóch lub więcej języków.
Fonetykę, jak zresztą każdą inną dziedzinę wiedzy, można pojmować synchronicznie i diachronicznie. To kolejny podział fonetyki; kryterium wydzielenia tych dwóch działów jest już nie przedmiot badań, lecz niejako stosunek: przedmiot badań a czas. Fonetykę synchroniczną (inaczej opisową, choć termin fonetyka opisowa może też oznaczać „fonetyka opisująca tylko jeden język” w opozycji do fonetyki porównawczej) interesuje stan fonetycznej strony języka w danym momencie czasowym. „Moment czasowy” oznacza tu pewien okres na tyle długi, by można w nim przeprowadzić odpowiednie badania, zebrać materiał badawczy, a jednocześnie na tyle krótki, żeby można było mówić o względnie niezmiennej fonetyce danej społeczności. Można więc przyjąć, że jest to okres kilkunastu lat, okres życia jednego pokolenia.
Fonetykę synchroniczną może interesować stan współczesnego języka, stan języka w XVI w. itd. Fonetykę diachroniczną interesuje zmiana, ewolucja fonetycznej strony języka. Aby ustalić, co w fonetyce się zmieniło i czy w ogóle miała miejsce jakaś zmiana, trzeba porównać ze sobą przynajmniej dwa stany systemu językowego, stany języka w dwóch momentach historycznych: wcześniejszym i późniejszym, a więc skorzystać z ustaleń fonetyki synchronicznej tych okresów.
Generowanie głosu
Głos ludzki powstaje przy współudziale szeregu narządów anatomicznych:
- krtań z umieszczonymi w niej strunami głosowymi
- oskrzela, tchawica i płuca wraz z mięśniami brzucha, mięśniami dna miednicy i przepona
- jama gardłowa i jama nosowa wspólnie zwane nasadą
- język, zęby, wargi, podniebienie
Na instrumentach strunowych z gryfem efekt ten uzyskuje się poprzez przesunięcie palcem po strunie na gryfie podczas wydobywania dźwięku, na instrumentach klawiszowych szybko przesuwa się palcem po białych lub czarnych klawiszach, na harfie – po strunach, natomiast na puzonie należy przesunąć suwakiem cały czas dmąc w instrument. Na harfie, dzięki jej systemowi pedałowemu, wyjątkowo da się wykonać glissando, które składa się z kilku zdublowanych dźwięków lub też z przemieszanych dźwięków wyższych i niższych.
Glissanda są stosowane również w śpiewie (niezamierzone glissanda są jednak często spotykanym i rażącym błędem w sztuce śpiewaczej).
Sposób zapisu glissanda
 Glissando w zapisie nutowym
Glissando w zapisie nutowymGlissando oznacza się słowem glissando (lub gliss.) oraz linią prostą lub falistą od nuty, którą rozpoczynamy glissando do nuty, na której je kończymy.
Intonacja w muzyce to krótka, wstępna fraza muzyczna, która ułatwia „zgranie” się osób przystępujących do wykonania właściwego utworu.W niektórych rodzajach muzyki dawnej (np. w chorale gregoriańskim intonacja była sztuką samą w sobie i pełniła rolę specjalnego, wstępnego ornamentu muzycznego.
„Intonacja” to przy użyciu określeń „czyste” lub „nie czyste” sprecyzowanie dokładności wykonania właściwej, zapisanej w utworze muzycznym wysokości danego dźwięku. Pojęcie „intonacji” stosuje się w tym wypadku do wykonania muzyki głosem lub przez instrumenty smyczkowe i dęte.
 Kamerton (diapazon) – przyrząd służący do strojenia instrumentów muzycznych.
Kamerton (diapazon) – przyrząd służący do strojenia instrumentów muzycznych.
Najczęściej w postaci jednotonowego instrumentu, nastrojonego na stałe na dźwięk a1 w stroju wiedeńskim = 440 Hz. Dźwięk ten został nazwany kamertonem, jako że służył za podstawę w muzyce kameralnej, kiedyś rozumianej wyłącznie jako instrumentalna (strój chóru był niższy). Nazwa diapazon wzięła się stąd, że do tonu podstawowego dostosowywane są pozostałe wysokości dźwięków w obrębie oktawy (w średniowieczu nazywanej diapazonem).
Wynalazcą kamertonu w 1711 był John Shore (1662–1752), lutnista angielskiego dworu.
Rodzaje kamertonów:
• widełkowy – widełki z niehartowanej stali, w które uderza się, aby uzyskać dźwięk
• stroikowy (gwizdkowy) – metalowa rurka z umieszczonym wewnątrz języczkiem z metalu (na wzór harmonijki ustnej)
• chromatyczny – połączone kamertony stroikowe w obrębie c1-c2.
Zastosowanie
Poza podstawowym, muzycznym zastosowaniem, kamerton (głównie widełkowy) używany był jako źródło dźwięku prostego (tonu) w nauce i technice. W tej funkcji stosowany jest obecnie głównie w laboratoriach dydaktycznych.
![]()
Kastraci z „wielką pieczęcią” służyli w haremach.
Kastraci z „małą pieczęcią”, wykastrowani przed okresem dojrzewania, charakteryzowali się pięknymi głosami, sopranami lub altami, typowymi dla kobiet, lecz o wiele potężniejszym brzmieniu i dramatycznej barwie. W okresie największego rozkwitu opery kastraci byli obsadzani w rolach, gdzie były potrzebne tzw. „głosy anielskie”. Szczególne zapotrzebowanie na kastratów w operze wiąże się z zakazem papieskim, obowiązującym w latach 1588-1793, który zabraniał kobietom publicznych występów. Chociaż papież Sykstus V surowo zabronił kastracji młodych chłopców w konstytucji Cum frequenter z 1587.
 Wielu kompozytorów, np. Georg Friedrich Haendel, pisało role specjalnie dla konkretnych kastratów. Niektórzy z nich zdobyli wielką sławę, odpowiadającą dzisiejszym gwiazdom estrady. W połowie XVIII wieku w Europie opinia publiczna uznała kastrację za barbarzyństwo i praktyka kastrowania młodzieńców została oficjalnie potępiona. Stała się ukrywanym procederem. W połowie XIX wieku ostatecznie została uznana za bezprawną i karalną. Do czasu zakazu papieskiego w 1903, kastraci śpiewali w chórach kościelnych, między innymi w słynnym chórze Kaplicy Sykstyńskiej, w Watykanie. Ostatni znany kastrat – Alessandro Moreschi, znany jako Rzymski Anioł, zmarł w 1922 roku. Zachowały się mechaniczne nagrania jego głosu dokonane w latach 1902 i 1904.Dziś partie kastratów śpiewane są przez soprany dramatyczne, kontratenory lub alty.
Wielu kompozytorów, np. Georg Friedrich Haendel, pisało role specjalnie dla konkretnych kastratów. Niektórzy z nich zdobyli wielką sławę, odpowiadającą dzisiejszym gwiazdom estrady. W połowie XVIII wieku w Europie opinia publiczna uznała kastrację za barbarzyństwo i praktyka kastrowania młodzieńców została oficjalnie potępiona. Stała się ukrywanym procederem. W połowie XIX wieku ostatecznie została uznana za bezprawną i karalną. Do czasu zakazu papieskiego w 1903, kastraci śpiewali w chórach kościelnych, między innymi w słynnym chórze Kaplicy Sykstyńskiej, w Watykanie. Ostatni znany kastrat – Alessandro Moreschi, znany jako Rzymski Anioł, zmarł w 1922 roku. Zachowały się mechaniczne nagrania jego głosu dokonane w latach 1902 i 1904.Dziś partie kastratów śpiewane są przez soprany dramatyczne, kontratenory lub alty.
Carlo Broschi znany jako Farinelli – jeden z ostatnich wielkich kastratów w historii opery.
Na najwyższym profesjonalnym poziomie niezbędne jest by śpiewak stale ćwiczył, gdyż w przeciwnym wypadku skala jego głosu może ulec znacznemu zmniejszeniu. Z uwagi na fakt, iż śpiew jest bardzo naturalną czynnością, taki typ ciągłych ćwiczeń poza obszarem muzyki klasycznej zwykle nie jest konieczny dla pół-profesjonalnych wokalistów.
Skale niektórych rodzajów ludzkiego głosu
|
Rodzajami ludzkiego głosu są (w kolejności, w grupie żeńskiej i męskiej odrębnie, od głosów o skali w najwyższym rejestrze do najniższego rejestru:
|
Skale niektórych rodzajów ludzkiego głosu: Sopran:  Alt: Alt:
Tenor:
|


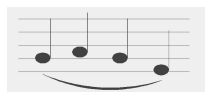 Legato jest techniką artykulacji w grze na instrumentach muzycznych, w której kolejne dźwięki są grane płynnie, bez najmniejszych przerw. W ten sposób tworzy się kilku(nasto) nutowe „potoki” dźwięku, w których nie sposób jednoznacznie wyodrębnić pojedyncze dźwięki. W naturalny sposób legato zamyka się we frazie.
Legato jest techniką artykulacji w grze na instrumentach muzycznych, w której kolejne dźwięki są grane płynnie, bez najmniejszych przerw. W ten sposób tworzy się kilku(nasto) nutowe „potoki” dźwięku, w których nie sposób jednoznacznie wyodrębnić pojedyncze dźwięki. W naturalny sposób legato zamyka się we frazie.W grze na gitarze legato wykonuje się za pomocą lewej ręki, której palce uderzają z odpowiednią siłą w struny powodując podtrzymanie drgania struny. W grze legato uderzenia kostki są sporadyczne i służą głównie do akcentowania frazy.

Melizmat na słowie Alleluia w Vigilia NativitatisMelizmatyka jest charakterystyczna dla śpiewu ambrozjańskiego, chorału gregoriańskiego (zwłaszcza na słowach Amen lub Alleluja) i muzyki orientalnej. Jest często stosowana w charakterze ornamentyki muzycznej we współczesnej muzyce popularnej.
Rozbudowane melizmaty na słowie Alleluja są nazywane jubilacjami. W muzyce średniowiecznej przyczyniły się do powstania nowego gatunków muzycznych – tropów i sekwencji.
![]()
 Metronom (miaromierz, taktomierz) – urządzenie mechaniczne lub elektroniczne służące do dokładnego podawania tempa utworu muzycznego. Przyrząd używany podczas ćwiczeń muzycznych oraz komponowania.
Metronom (miaromierz, taktomierz) – urządzenie mechaniczne lub elektroniczne służące do dokładnego podawania tempa utworu muzycznego. Przyrząd używany podczas ćwiczeń muzycznych oraz komponowania.Metronom mechaniczny wynaleziony został w 1816 r. przez J. N. Mälzla. Starsze wersje posiadały charakterystyczną drewnianą obudowę w kształcie zbliżonym do graniastosłupa, w XX wieku do obudowy stosowano ebonit lub plastik. Zbudowany jest z mechanizmu zegarowego napędzanego sprężyną, oraz wystającego do góry wahadła będącego jednocześnie skalą, po której przesuwać można ciężarek, umieszczając go przy zadanej wartości tempa. Wahadło przechodząc przez środkowe położenie wydaje charakterystyczny, dość głośny stuk. Skala jest wycechowana od 40 do 208 wychyleń wahadła na minutę, co odpowiada stosowanej współcześnie mierze uderzeń na minutę (BPM). W niektórych wersjach dodatkowo montuje się dzwonek, który akcentuje co drugie, co trzecie, lub co czwarte uderzenie.
Metronom w niemal nie zmienionej formie przetrwał do naszych czasów, choć coraz częściej korzysta się z jego elektronicznych odpowiedników.
Ozdobnik – element melodii wprowadzający dodatkowe dźwięki mające charakter ornamentów.
W dawnych czasach stosowanie ozdobników zależało od smaku i inwencji wykonawcy, lecz z czasem ustalono pewien zasób standardowych ozdobników i zasady ich zapisu. Ozdobniki nie zwiększają czasu trwania taktu i wykonywane są kosztem czasu dźwięku, który ozdabiają, lub dźwięku poprzedzającego.
Ornamentyka była bardzo popularna w muzyce dawnej, baroku i muzyce klasycystycznej. Szczególną mnogość ornamentów wypracowała muzyka klawesynowa. Do czasów współczesnych zachowały się tylko niektóre, a i te są rzadko używane.
Śpiew z użyciem ozdobników nazywa się koloraturą (zob. też sopran koloraturowy).
Do używanych dziś ozdobników należą:
- przednutka krótka
- przednutka długa
- mordent
- obiegnik (gruppetto)
- tryl
- ornament
- arpeggio

Więzadła głosowe mają różną długość u kobiet i mężczyzn. U mężczyzn są na ogół dłuższe (niższa barwa głosu) – od 17 do 25 mm. Kobiety, jako zazwyczaj mniej umięśnione, mają także odpowiednio krótsze fałdy głosowe (długości 12-17 mm).
Więzadła głosowe znajdują się powyżej tchawicy. Pożywienie nie przechodzi przez nie – reguluje to przełyk, automatycznie blokując drogi oddechowe przy przełykaniu. Gdy jedzenie dostanie się do tchawicy, powoduje duszenie się.
Więzadła głosowe znajdują się w krtani. Są przytwierdzone od strony rdzenia kręgowego do wyrostków głosowych znajdujących się na parzystych chrząstkach nalewkowatych, a z drugiej do chrząstki tarczowatej. Składają się głównie z nabłonka, ale fałdy głosowe, znajdujące się najniżej chrząstki tarczowatej zawierają włókna mięśniowe. Więzadła głosowe nie są połączone, tworzą dziurę szparę głośni. Gdy szpara jest szeroka, powietrze przepływa swobodnie, gdy zaś jest zwężona, powietrze opływa fałdy głosowe, powodując ich drganie (wytwarzanie dźwięku). Wysokość głosu zależy od napięcia fałd głosowych, a głośność od szybkości przepływu powietrza.
Różnice w budowie fałd głosowych powodują różne brzmienie głosu u poszczególnych osób, także w obrębie tej samej płci (wysokość głosu).
Dźwięk skierowany przez małżowinę uszną do przewodu słuchowego zewnętrznego wprawia w drgania błonę bębenkową i tzw. aparat akomodacji tj.kosteczki słuchowe i mięśnie ucha środkowego.Dzięki ruchom podstawy ostatniej z trzech kosteczek-strzemiączka-w okienku owalnym błędnika, drgania akustyczne przenoszą się na płyny, jakimi wypełniony jest ślimak.Ponieważ płyny są nieściśliwe, na to aby podstawa strzemiączka mogła wykonać ruch w głąb ucha wewnętrznego musi dojść do kompensacyjnego wychylenia-w stronę jamy bębenkowej-błony drugiego okienka ucha wewnętrznego zwanego okrągłym.Ta tzw. gra okienek jest niezbędnym warunkiem prawidłowego przenoszenia dźwięków drogą powietrzną, bębenkowo-kosteczkową.
Wyróżniamy kilka rejestrów głosu, w tym główne: rejestr piersiowy, rejestr głowowy i rejestr gwizdkowy. Śpiew na niedomkniętych strunach głosowych to falset. Głos źle ustawiony, produkujący dźwięki o błędnej częstotliwości (wysokości) jest głosem fałszywym
Rejestr piersiowy – pojęcie z techniki wokalnej służące do określenia rezonansu odczuwalnego w okolicy klatki piersiowej przez osobę śpiewającą; skala naturalnego głosu mówionego śpiewaka/śpiewaczki;
Rejestr głowowy – pojęcie z techniki wokalnej służące do określenia odczuwalnego przez śpiewaka w głowie rezonansu. Odwołując się między innymi do książki Davida Clippingera z początku XX wieku stwierdza się, że wszystkie głosy posiadają rejestr głowowy, zarówno bas, jak i sopran. Wspomina się o nim także w metodzie śpiewu Speech Level Singing.
- Zmysł umożliwiający odbieranie (percepcję) fal dźwiękowych. Narządy słuchu nazywa się uszami. Słuch jest wykorzystywany przez organizmy żywe do komunikacji oraz rozpoznawania otoczenia.
- Słuch relatywny – ważny w edukacji muzycznej rodzaj słuchu polegający na umiejętności odmierzania interwałów względem podanego dźwięku wzorcowego.
- Słuch absolutny – powszechnie określany, jako słuch doskonały to rzadko spotykana umiejętność człowieka do rozpoznawania lub odtwarzania nut bez korzystania z zewnętrznego odniesienia czyli inaczej trwała pamięć pewnych specyficznych właściwości dźwięków, akordów czy tonacji która umożliwia ich rozpoznawanie bez odwoływania się do dźwięku wzorcowego. Jest on preferowany choć nie wymagany przy edukacji muzycznej. Jest to rzadko spotykana wśród ludzi wrodzona umiejętność rozpoznawania bezwzględnej wysokości dźwięku jedynie na podstawie jego percepcji sensorycznej, bez porównywania z innym dźwiękiem, czy też innej spekulacji intelektualnej. Jest związany z rozbudowanymi koniuszkami nerwów słuchowych, a także oznacza rozszerzoną skalę słuchu człowieka. Dotyczy rozpoznawania także kilku dźwięków równocześnie.
Słuch absolutny w praktyce
Słuch absolutny można wykryć u dziecka kształconego muzycznie w wieku od 4 do ok. 12 lat. Przez wielu uważany za uciążliwość. Utrudnia bowiem wokalistom śpiewanie z nut i jednoczesną transpozycję do innej tonacji, strojenia instrumentu do innego dźwięku A (np. 438 Hz), a dla niektórych nawet uczucie dyskomfortu podczas słuchania znanej im piosenki w innej tonacji. Z wiekiem może ulegać zatracaniu, choć nie zdarza się to często.Nauka słuchu absolutnego
Wiele osób z rozwiniętym słuchem muzycznym może wypracować zdolność rozpoznawania tonacji utworu, a czasem nawet pojedynczych dźwięków za pomocą ich barwy czyli ułożenia szeregu alikwotów (tony składowe).
Istnieją jednak sprawdzone metody nauczania słuchu absolutnego (praktykowane w wielu uczelniach muzycznych na całym świecie).
Słuch człowieka – podstawowe dane
| zakres słyszalnych częstotliwości Zakres największej czułości ucha Zakres częstotliwości ludzkiej rozmowy Próg słyszalności Próg bólu Uszkodzenie słuchu Zakres rejestrowanych zmian ciśnienia Minimalne wychylenie błony bębenkowej Wychylenie błony bębenkowej przy głośnym dźwięku o niskiej częstości Liczba rozróżnialnych czystych tonów Rozdzielczość częstotliwościowa ucha Rozdzielczość kątowa ucha Rozdzielczość czasowa ucha Ubytek słuchu z wiekiem (18-50 lat) Ubytek słuchu z wiekiem (powyżej 50 lat) Przeciętny ubytek słuchu w wieku 70 lat Wyprzedzenie oko-usta przy czytaniu na głos |
16-20000 Hz
1000-3000 Hz 200-3000 Hz 0 dB 110-140 dB 150 dB 0,00002-60 Pa 10 − 11 m 0,1 mm ~3000 1 Hz przy 1000 Hz 1-4° 0,05 s 0,5 dB/rok 1 dB/rok 37 dB
|
W grze na gitarze, harfie czy innych instrumentach strunowych szarpanych staccato wykonuje się poprzez natychmiastowe uciszenie struny po jej szarpnięciu, lub poprzez szarpanie strun już lekko przytrzymanych.
W przypadku instrumentów klawiszowych staccato polega na szybkim uderzeniu w klawisz i poderwaniu w górę dłoni w nadgarstku.
W instrumentach smyczkowych staccato polega na „puszczeniu” smyczka, żeby się zatrzymał, lub oderwaniu go od struny.
 W instrumentach dętych z kolei na skróceniu trwania dźwięku oraz specyficznym ataku (np. na trąbce przez delikatnie ostrzejszy atak na sylabie ta). Wyróżnia się ponadto dwa rodzaje staccata na instrumentach dętych, umożliwiające szybszą repetycję: podwójne oraz potrójne.
W instrumentach dętych z kolei na skróceniu trwania dźwięku oraz specyficznym ataku (np. na trąbce przez delikatnie ostrzejszy atak na sylabie ta). Wyróżnia się ponadto dwa rodzaje staccata na instrumentach dętych, umożliwiające szybszą repetycję: podwójne oraz potrójne.W notacji muzycznej staccato zaznacza się kropką nad nutą.
Rodzaje śpiewu
Wyróżnia się śpiew utworów muzycznych z tekstem – śpiew sylabiczny, melizmatyczny – oraz pozbawiony cech mowy – wokaliza. Natomiast śpiew z zamkniętymi ustami to mormorando. Śpiew może być nieformalny i wykonywany dla przyjemności, a także formalny, taki jak profesjonalny śpiew na przedstawieniu, koncercie, bądź w studio nagraniowym. Śpiewanie na wysokim amatorskim bądź profesjonalnym poziomie wymaga dużej ilości regularnych ćwiczeń lub/i nauczyciela. Wysokiej klasy śpiewacy posiadają instruktora śpiewu oraz trenują przez cały czas trwania ich kariery.
Śpiew może być wykonywany w grupie, takiej jak chór, przy akompaniamencie instrumentów muzycznych, pełnej orkiestry lub zespołu. Śpiewanie bez akompaniamentu muzycznego nazywamy śpiewem a cappella.
- Bel canto
- Speech Level Singing
Wokaliza (łac. vocalis – samogłoska) – rodzaj śpiewu, polegający na wykonywaniu melodii na jednej samogłosce (najczęściej a). Może służyć jako ćwiczenie wokalne, a także być częścią utworu muzycznego (np. Vocalise Siergieja Rachmaninowa).
Termin ten bywa także używany dla określenia prawidłowej artykulacji głosek w śpiewie; dotyczy to zwłaszcza samogłosek.
Wokaliza w śpiewaniu jazzowym scat – instrumentalny sposób traktowania głosu, polegający na śpiewaniu linii melodycznych (solo instrumentalne) bez użycia konkretnych słów, np bi-bop, ta-ra, ta-ka itp.
Mistrzowie scatu to najczęściej wokaliści jazzowi: Louis Armstrong, Ella Fitzgerald, Al Jarreau, Kurt Elling, a w muzyce dance Scatman John. W Polsce: Anna Serafińska, Janusz Szrom, Urszula Dudziak, Karolina Glazer.